So far we have been working with only 1 independent variable at a time. It’s time to move on to multiple predictors.
What is statistical control?
When we include more than one predictor we often say that we are controlling for a number of variables in the model. This innocent-sounding term can actually sometimes cause quite a head ache to wrap your head around it. What does it mean to control for a variable?
One seemingly simple answer is that controlling means estimating the effect of one variable while holding the other variable constant. We’ll look at what exactly that means in this class. As a first approximation lets make a simple graphical interpretation of statistical control. We will denote x as the min independent variable, u as the control variable and y as the dependent variable.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
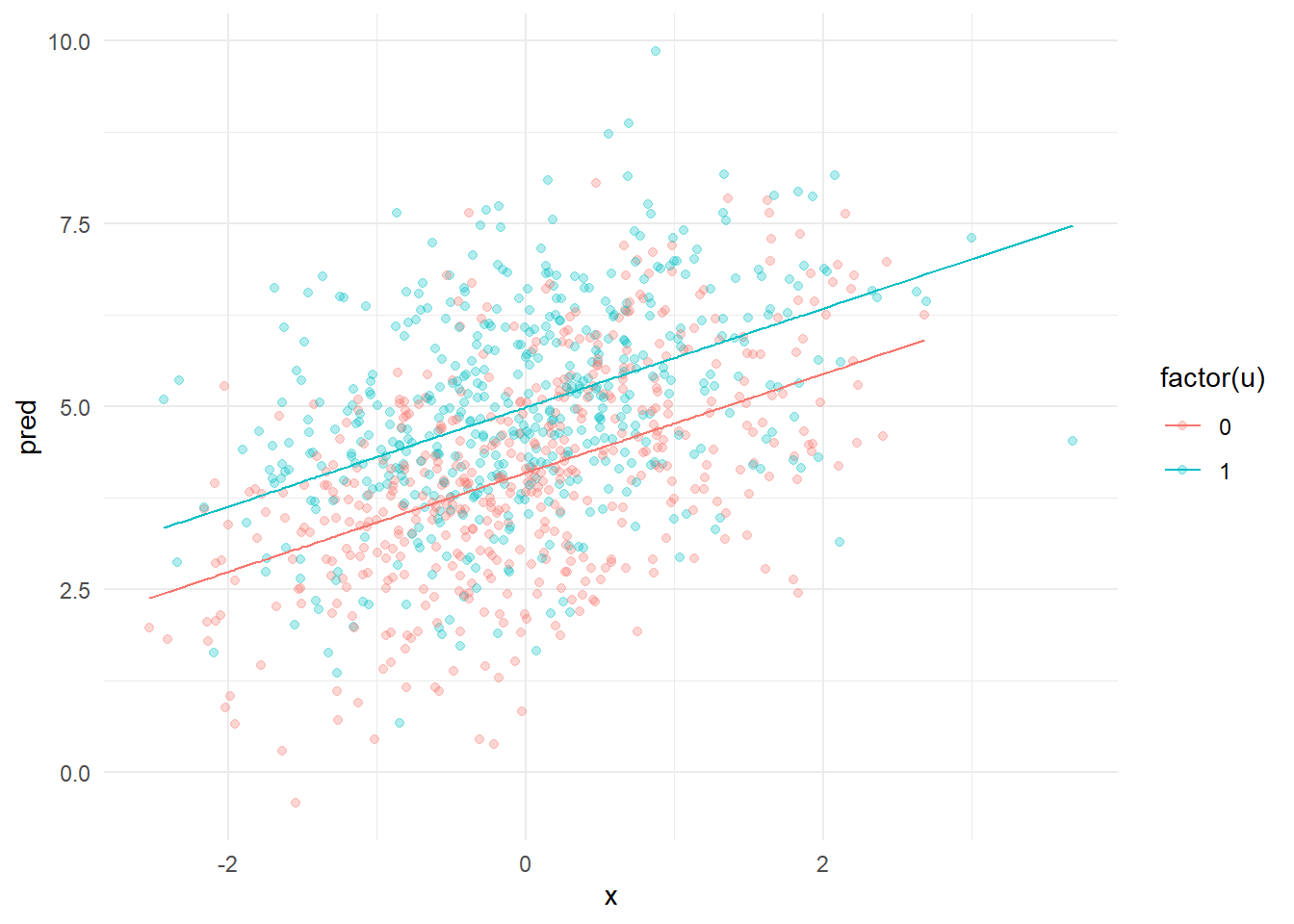
N <-1e3x <-rnorm(N)u <-rbinom(N,1,.5)y <-rnorm(N, 4+ .7*x +1*u, 1.3)df <-data.frame(x, u, y)df$pred <-lm(y ~ x + u, df) |>predict() # get predicted values from the model#plot predictions and raw data df %>%ggplot(aes(x = x, y = pred, color =factor(u), group =factor(u))) +geom_point(aes(x = x, y = y, color =factor(u)),alpha = .3) +geom_line() +theme_minimal()
You can see the effects plotted. The lines show the effects of x on y. Each level of u has its own line. Notice that both lines have the same slope - regardless of the level of u the effect of x on y is the same. This is exactly what statistical control means in this case. The effect of u can be understood as the distance between both lines. Again notice that it is the same across the entire range of the lines. No matte what value of x we take the effect of u is the same. Likewise for the effect of x.
We can try a similar thing with 2 continuous predictors but this is going to be more difficult to plot as we are still working in 2 dimensions. One trick we can use is to plot the effect of x on y for various levels of u (lets say quantiles).
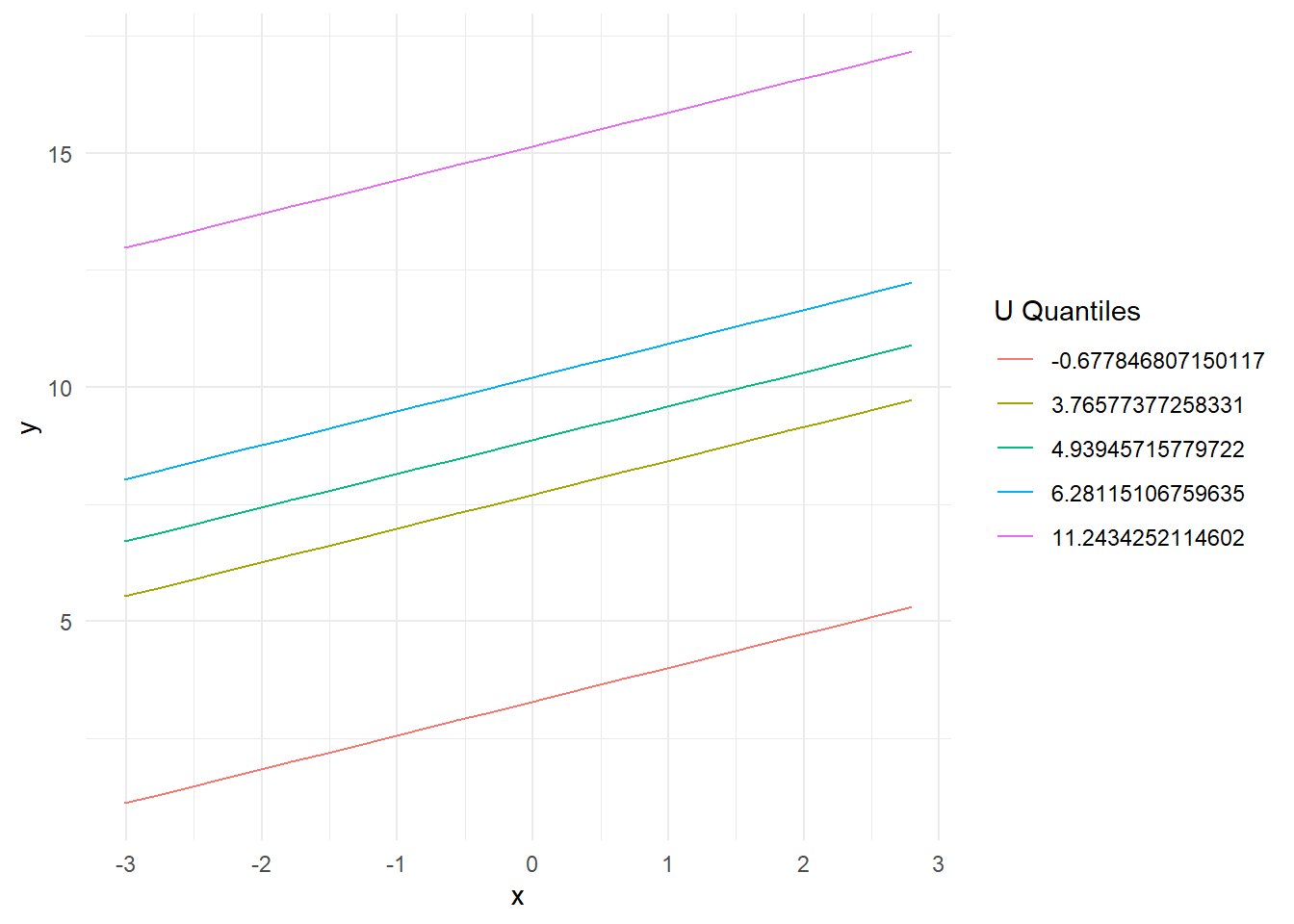
N <-1e3x <-rnorm(N)u <-rnorm(N,1+ .3*x, 1)y <-rnorm(N, 4+ .7*x +1*u, 1.3)df <-data.frame(x, u, y)model_2<-lm(y ~ x + u, df) # get predicted values from the modelpred.data =expand.grid(x =seq(min(df$x), max(df$x), length=20),u =quantile(df$y))pred.data$y =predict(model_2, newdata=pred.data)ggplot(pred.data, aes(x, y, colour=factor(u))) +geom_line() +labs(colour="U Quantiles") +theme_minimal()
You can again see that the slope for x is the same at each quantile of u. This means that in our model for any value of u the effect of x on y is the same. If we reversed it we would see the same thing for u.
To control or not to control?
Why do we add control variables into the model? We can think about two basic reasons: to make better predictions or to adjust the effect of one variable to account for confounding. The first case is tied to prediction problems - adding additional information should make our predictions better right? The second case has a lot to do with the “correct model specification” assumption for linear models. If there is an important variable that should be included in the model but we did not do it then our effect is going to be biased. Such variables are called confounders. However they can take different forms depending on exactly how the relations between variables look like. A really good paper on this topic is here.
I think one of the clearest ways to see how different confounders affect the model is to simulate them. This way we know exactly what the correct answers are and how including the confounder affects the model. The basic types of confounds are: fork, mediator, collider and descendant. In each of the simulated situations below we will work with 3 variables x is our independent variable, y is our dependent variable and u is the confounder.
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-5.1783 -0.9130 0.0027 0.9192 5.3928
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.54079 0.06329 40.15 <2e-16 ***
x 0.57054 0.01128 50.59 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.336 on 9998 degrees of freedom
Multiple R-squared: 0.2038, Adjusted R-squared: 0.2037
F-statistic: 2560 on 1 and 9998 DF, p-value: < 2.2e-16
lm(y ~ x + u) |>summary()
Call:
lm(formula = y ~ x + u)
Residuals:
Min 1Q Median 3Q Max
-4.8958 -0.8728 -0.0111 0.9016 4.9523
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.05292 0.06512 31.52 <2e-16 ***
x 0.40579 0.01307 31.04 <2e-16 ***
u 0.27895 0.01200 23.24 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.301 on 9997 degrees of freedom
Multiple R-squared: 0.2446, Adjusted R-squared: 0.2445
F-statistic: 1619 on 2 and 9997 DF, p-value: < 2.2e-16
You can see that not including u in the model gives us the wrong answer. This is the confounding that people most commonly have in mind when they are controlling for things in their models.
mediator
A mediator is a variable that is affected by x and affects y.
This issue also pops up in what is called the port-treatment bias. Basically it boils down to controlling for variables that are downstream of your treatment (be it in experiment or in an observational study). For example if you ran a randomized experiment and measured a bunch of things should you control for something measured after the experimental manipulation? If you are interested in the effect of the experiment then the anwser is no. There are even much more subtle ways in which post treatment bias can creep in - e.g. excluding participants who failed an attention check after the manipulation is effectively introducing post treatment bias. After all you are holding constant the value of a variable “passed attention check”. You can read about it here.
Collider
A collider is a variable that is affected by both x and y.
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-5.0588 -0.8843 0.0078 0.8711 4.8444
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.01046 0.04111 48.90 <2e-16 ***
x 0.39406 0.01300 30.32 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.314 on 9998 degrees of freedom
Multiple R-squared: 0.0842, Adjusted R-squared: 0.08411
F-statistic: 919.3 on 1 and 9998 DF, p-value: < 2.2e-16
lm(y ~ x + u) |>summary()
Call:
lm(formula = y ~ x + u)
Residuals:
Min 1Q Median 3Q Max
-4.9615 -0.8383 -0.0038 0.8308 5.0082
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.503659 0.065634 7.674 1.83e-14 ***
x 0.225277 0.013802 16.322 < 2e-16 ***
u 0.270052 0.009392 28.752 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.263 on 9997 degrees of freedom
Multiple R-squared: 0.1541, Adjusted R-squared: 0.154
F-statistic: 910.9 on 2 and 9997 DF, p-value: < 2.2e-16
This one is particularly bad because here including u gives us the wrong answer! It is worth spending a little more time on colliders because they are particularly insidious and can creep in where you expect them the least.
One way in which a collider can creep in is through selection bias. Selecting based on a variable effectively means controlling for it (as we are holding a variable constant). Below is a crude example
Call:
lm(formula = y_c ~ x_c, data = df_c %>% filter(u_c >= 0.2))
Residuals:
Min 1Q Median 3Q Max
-2.1995 -0.5212 -0.0449 0.4589 4.3316
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.82705 0.01314 62.96 <2e-16 ***
x_c -0.30963 0.01278 -24.22 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7428 on 4158 degrees of freedom
Multiple R-squared: 0.1237, Adjusted R-squared: 0.1234
F-statistic: 586.7 on 1 and 4158 DF, p-value: < 2.2e-16
In our simulation there is no relation between x_c and y_c but if we select for only certain values of u_c which is a collider we are inducing a spurious relation! This can become clearer once we plot the data:
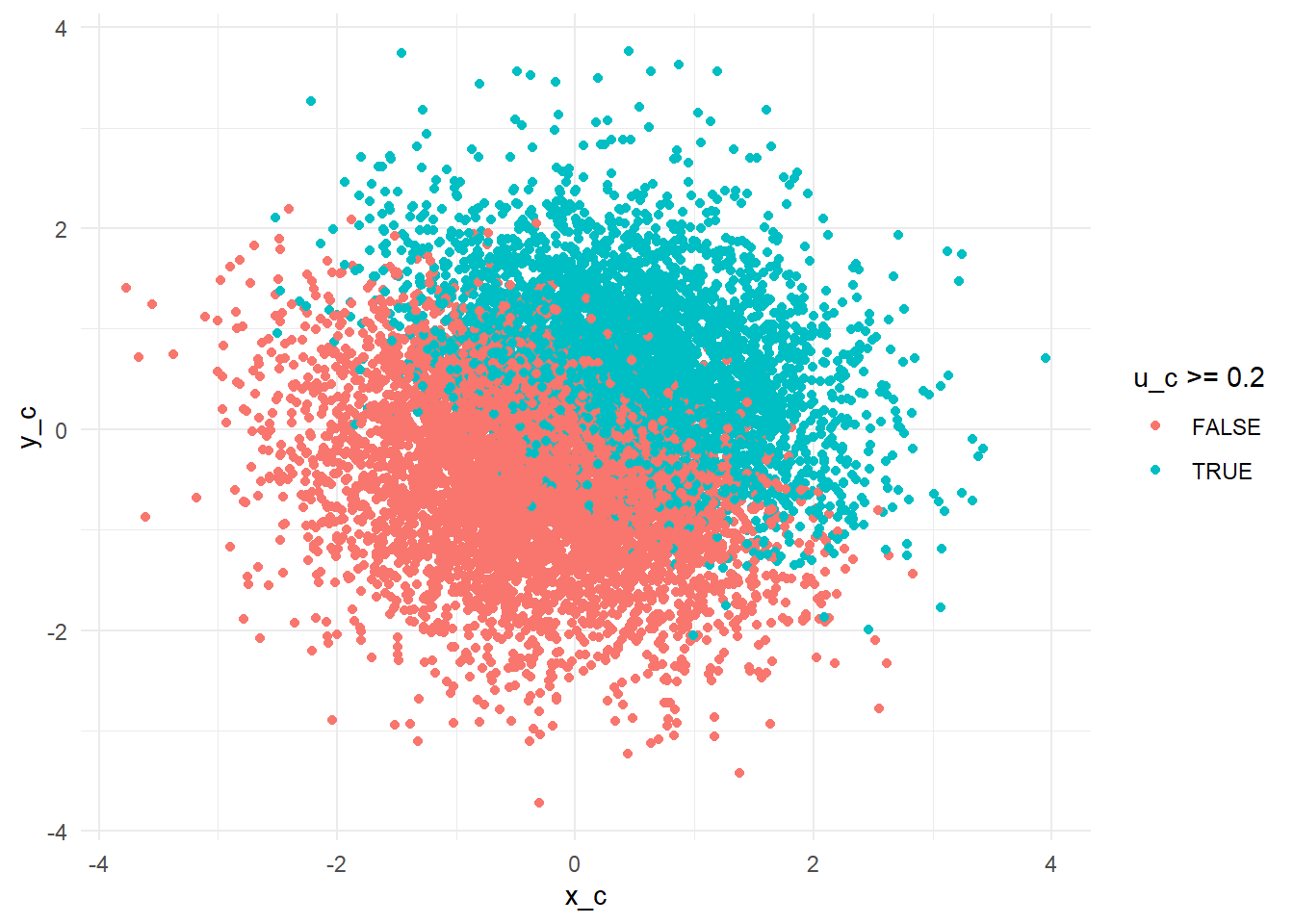
df_c %>%ggplot(aes(x = x_c, y = y_c, color = u_c >= .2)) +geom_point() +theme_minimal()
We can see there is no relation in the entire dataset but in the subgroup of u_c >= .2 there seems to be one! But this is only because u_c is itself a product of x_c and y_c so that is has higher values for high x_c and y_c. u_c takes high values if either x_c, y_c or both have a high value and this induces the spurious correlation.
This problem can be especially tricky if you think about surveys with voluntary participation. If both your independent and dependent variable affect willingness to participate in the survey (e.g. you are interested in assessing the effect of number of hours worked per week on mental health and people who work a lot and people with poor mental health are less willing to participate in your survey then you have a collider problem).
Descendant
A descendant is a variable that is affected by the confounder. We will denote the descendant as z.
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-5.3280 -0.8924 -0.0040 0.9072 5.2059
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.46759 0.06193 39.84 <2e-16 ***
x 0.58857 0.01105 53.26 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.338 on 9998 degrees of freedom
Multiple R-squared: 0.221, Adjusted R-squared: 0.2209
F-statistic: 2836 on 1 and 9998 DF, p-value: < 2.2e-16
lm(y ~ x + z) |>summary()
Call:
lm(formula = y ~ x + z)
Residuals:
Min 1Q Median 3Q Max
-5.3129 -0.8765 -0.0065 0.8822 5.0636
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.81073 0.06835 26.49 <2e-16 ***
x 0.46205 0.01241 37.23 <2e-16 ***
z 0.27060 0.01299 20.82 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.31 on 9997 degrees of freedom
Multiple R-squared: 0.2534, Adjusted R-squared: 0.2532
F-statistic: 1696 on 2 and 9997 DF, p-value: < 2.2e-16
lm(y ~ x + u) |>summary()
Call:
lm(formula = y ~ x + u)
Residuals:
Min 1Q Median 3Q Max
-5.3609 -0.8785 -0.0092 0.8702 5.1883
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.94413 0.06368 30.53 <2e-16 ***
x 0.41551 0.01278 32.51 <2e-16 ***
u 0.29490 0.01185 24.89 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.299 on 9997 degrees of freedom
Multiple R-squared: 0.2664, Adjusted R-squared: 0.2663
F-statistic: 1816 on 2 and 9997 DF, p-value: < 2.2e-16
The answer when controlling for the descendant is not perfect but it is much better than including just x. One way to think about it is that in some analyses it can serve as a proxy variable if the actual confound is difficult to measure.
Interpreting multiple regression
Lets say we have already ran a model with multiple predictors in it. How should we interpret the results? I have already told you that in such a case the effect of your main variable should be understood as “the effect of x while holding all other covariates constant”. How should we understand this in practice though? You should be aware that introducing a covariate changes the interpretation of the coefficient for the main variable of interest. This is especially stark in some situations where the variables you put in the model are conceptually linked to each other. Here’s an example I’ve seen somewhere (unfortunately can’t find where to give you a link).
Imagine you are predicting household income using family size and number of adults in the household. In such a model what does it mean to have an effect of family size while holding number of adults constant? Well, it’s the number of kids in the house! So including number of adults into the model completely changes the meaning of the family size variable. What then is the effect of number of adults while holding family size constant? This one then is pretty weird and much harder to interpret. Maybe it’s the effect of a kid becoming an adult?
Here’s another example from psychology: imagine you are predicting prejudice towards a group of people using the perceived warmth (how friendly this group’s intentions towards us seem) and competence (perceived capability to enact intent) as in classic Stereotype Content model. When we put both of them into the model we have to adjust our interpretations of the effects of warmth and competence. The effect of warmth becomes the effect of perceived intentions of the outgroup regardless of how capable to enact these intentions this group seems to be. Similarly the effect of competence has to be interpreted differently - as perceived ability to act on intentions regardles of whether they are good or bad.
This shows that throwing additional variables into the model can not only estimate wrong effects but render them pretty much uninterpetable.
Apart from changes in interpretation of the effect of the main variable you might be interested in interpretation of the effects of the covariates themselves. Imagine a model in which you predict verbal aggression with Social Dominance Orientation (a social darwinist worldview that the world is inherently hierarchical and groups fight each other for status and resources). You think that both of these are different between men and women so you control for gender in the model. What does the effect of gender mean here? You might be tempted to interpret it just as “the difference between men and women in verbal aggression while holding SDO constant”. But what does that really mean? Remember that we think that both SDO and verbal aggression are affected by gender and that SDO affects verbal aggression. This means that when we shift focus from SDO to gender SDO becomes a mediator! So the effect we get from our regression is the direct effect of gender and not the total effect. Casually interpreting the effects of covariates from a model is often called Table 2 fallacy. Always think carefully what a given effect represents because it is rarely obvious and simple. Here’s another great paper on this topic.
So what do I do?
From all of the above you might get the impression that working in the multivariate world is dangerous and you are pretty much destined to fall into one of the many traps of statistical control. There is indeed a lot of things that can go wrong very easily. So what should you do? The answer is always: think! Think carefully. This way you can at least prepare for potential problems and avoid misinterpretation. A humble and right result is infinitely better than a bombastic and wrong one. It;s much better to arrive at a conclusion that we can’t estimate a given effect than to estimate the wrong effect.
The software will (almost) always spit out some result. It is up to you to decide what it means and whether it makes any sense at all. You have to be able to say what the model can and what it can’t tell you. Being able to critique models (not in the sense of saying how they are wrong but carefully studying their limitations) is a skill that takes time to develop but with practice you can get really good at it and it will profit in the future.
One quite interesting debate recently that revolved around these issues is related to estimating the effect of social media use on mental health. Here are some examples using the concepts introduced above to get at that question (or more precisely how hard it is to answer this question)