We will finally move to actually running statistical models with general linear models. We’ll see that a simple t-test and between-subjects anova are just linear models.
Prediction and inference
Regression analysis is often described in two ways. One of them talks about how to predict a value of variable of interest given a set of other variables. The other context focuses on inference: which variables are in fact related to a variable of interest. When doing inference you are interested in learning how the data was generated as a function of your variables of interest. In prediction you just want to be as accurate as possible. This is of course a bit simplistic and as you’ll see looking at predicitons can be very useful for actual inference but this explanation will do for now.
As an example imagine you work in a real estate agency selling houses. You track information on a number of characteristics of each house: their price, size, number of rooms, distance from city center and various facilities etc. You might be interested in predicting the price of a house as accurately as possible given all the characteristics of a house. You might also be interested in how various characteristics of a house relate to its price so as to know what to focus on (e.g. what to invest in).
Regression engine
The very idea of making a regression analysis is to reexpress the relations between variables so as to be able to express one of them as a combination of the other ones. How can we do that? We want a way that will approximate our variable of interest so that each time we are to say what value this variable will have we will make the best guess possible. But what does it mean ‘the best guess possible’? We need some rule on what it would mean to make a best guess. Since we are predicting a continuous variable we can calculate how much we miss for every prediction (subtract the actual value from the predicted value) and then choose the one that has the smallest error. This is already a start but we can miss in two ways: we can predict too little or too much. The first one is going to produce a negative error and the other one a positive one. Negative numbers are smaller than positive ones so our rule so far will always favor predicting too little! Fortunately there is a very easy way to deal with this - we can square the errors (there are reasons why squaring is preferred to taking absolute values but they are beyond the scope of this course). Now, we can sum all the squared errors for each observation in our dataset. The prediction that gets the smallest sum of squared errors wins! This is pretty much how the Ordinary Least Squares (OLS) regression works.
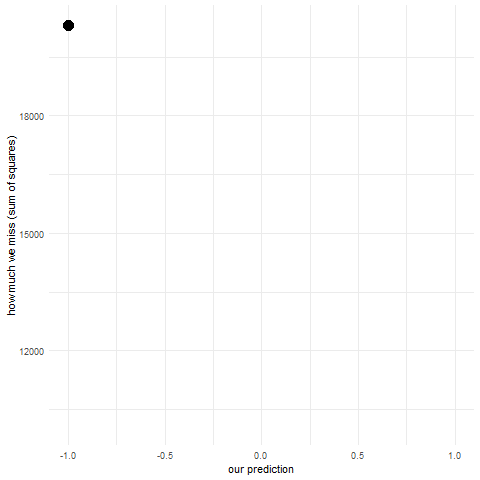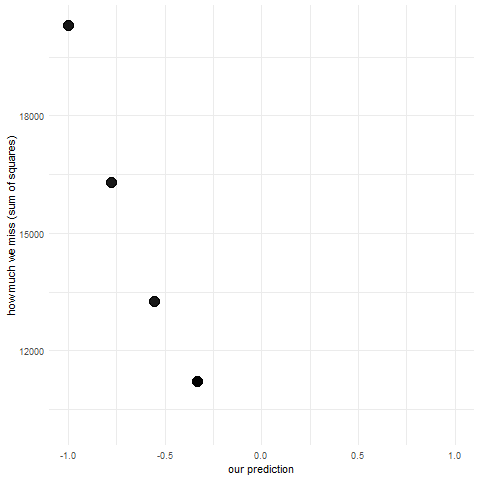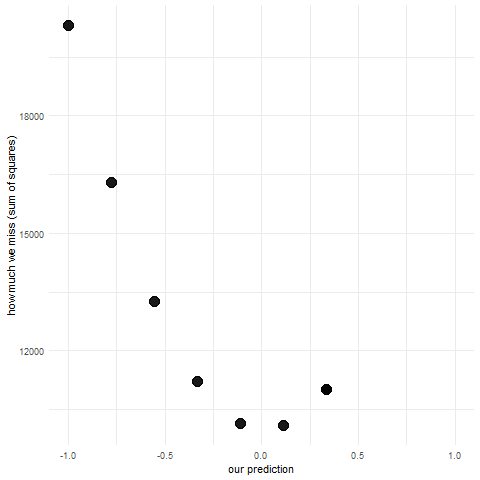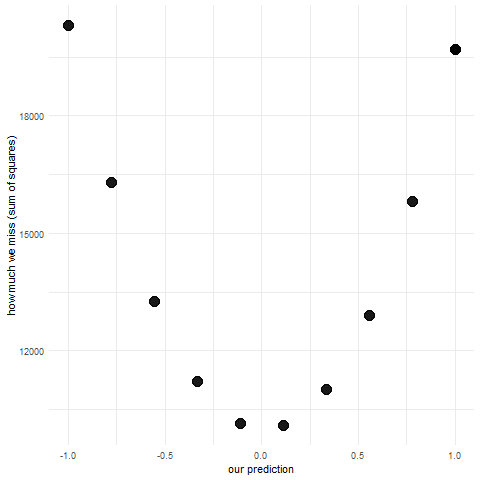
Lets start with the simplest example possible. Lets say we have no other information except our variable that we want to predict. Which value will minimize the sum of squared errors? There’s actually a fancy formula for this because OLS regression has a closed form but perhaps a better way to learn this is to actually make a bunch of guesses and see what happens. This is what simulation is perfect for.
Lets first simulate a bunch of observations from a normal distribution: our dependent variable. We will keep mean = 0 and standard deviation = 1.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
y <-rnorm(1000)
Next, we’ll make a bunch of guesses in the range from -1 to 1 and see how each of them performs (what is their sum of squared errors).
sse <-c() #initialize vector to store sum of squared errorspred <-seq(-1,1,length.out =10) #we'll make 10 guesses from -1 to 1, equally spacedfor (i in pred) { res <-sum((i - y)^2) # for each guess calculate sum of squared errors sse <-c(sse, res) #append the sum to the vector}pred_sse <-data.frame(pred,sse) #put these
You can go ahead and inspect the sse and pred. Can you see for which guess we get the smallest error? You can also look at the animation below:
predictions and sums of squared errors
You can see that the points fall on a really nice parabola. For a guess of mean - 1 standard deviation we get a really big sum of squared errors, they gradually get smaller and smaller and then start to get bigger up to mean + 1 standard deviation. The lowest point of the parabola is at the mean and that is in fact our best guess. When making regression analysis we will be working with means all the time. We’ll just be adding more information to the model (e.g. if we add belonging to experimental vs control group into the model, then our best guess will be the mean in each of those groups and we get a two sample t-test). Linear models are all about conditional means i.e. means of one variable given a value of another variable.
A more general way which we can use to think about linear models is that we are modelling Y as following a normal distribution with mean \(\mu\) and variance \(\sigma\). The mean is then determined by the variables we put into the model (those are the conditional means from above). If we don’t add anything \(\mu\) is going to be the actual mean in our sample. If we start adding variables into the model then \(\mu_i\) will be determined by them (that’s why we have the i).
\[
Y_i \sim Normal(\mu_i, \sigma)
\]
\[
\mu_i =\alpha
\]
When we add predictors into the model we will be able to assess how much we can improve over just using the mean of the dependent variable (in fact this is what one of the most commons metrics for assessing linear models is - R squared).
Making a simple regression
Before we move on to running our first model we have to understand one more thing - formulas in R. They allow us to write models in a very succint form. A formula generally takes the form of y ~ x1 + x2 + .... On the left hand side is always the dependent variable and on the right hand side you put all of your predictors.
We’ll start with a simple simulated example to get an intuition on what exactly a simple linear model does. We will simulate some data, run a model and then plot the predictions against the data.
N <-1e4x1 <-rnorm(N)y <-rnorm(N, 2+ .5*x1)df1 <-data.frame(x1, y)
Lets run a simple linear model:
lm_sim <-lm(y ~ x1, df1)
Ok, now we can get to the plotting. What we will do is:
Plot the original data
Plot the regression line
Plot the conditional distributions implied by the model.
You can inspect the code if you want but it’s not that important right now
simulating data implied by the model
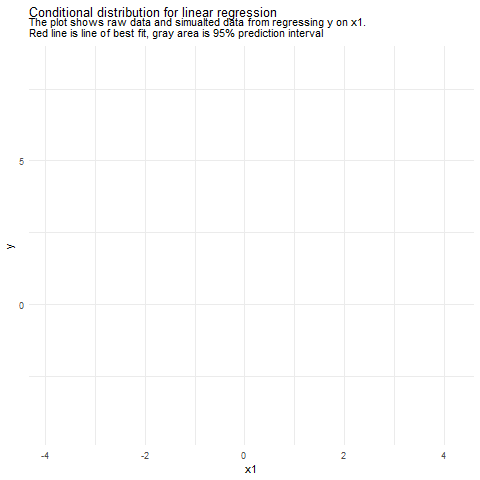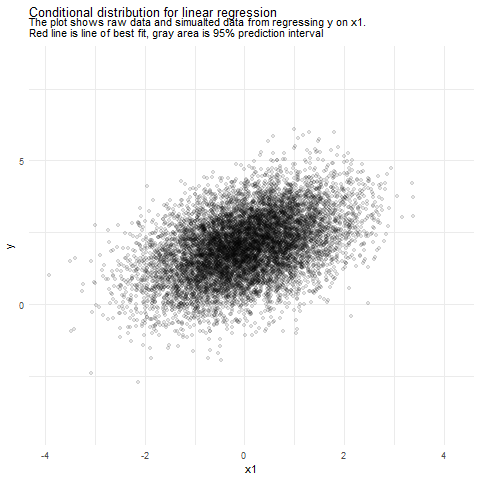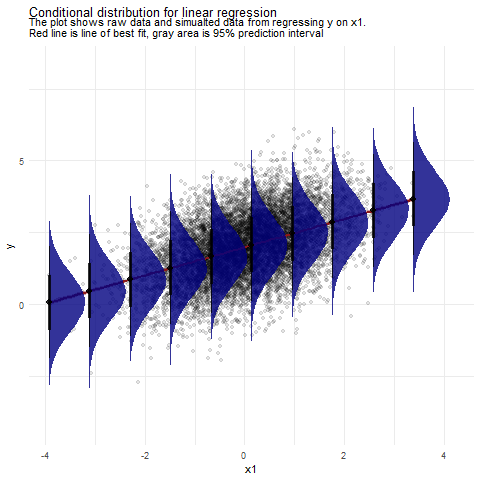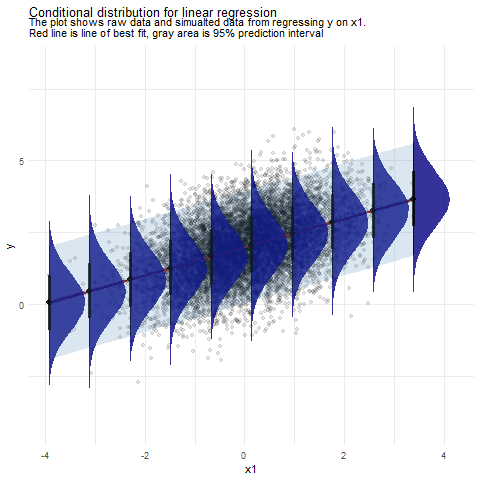
x1 <-seq(min(df1$x1), max(df1$x1), length.out =10)#set up a data frame to store simulated valuesdf_sim <-data.frame(x1 =numeric(), sim =numeric())#run loop for simulationfor(i in x1) {#simulate y for given x1 sim <-rnorm(1e5, mean = lm_sim$coefficients[[1]] + lm_sim$coefficients[[2]]*i, sd =1)#store x1 for given simulations x1_1 <-rep(i, 1e5)#store sim and x1 in temp temp <-data.frame(x1 = x1_1, sim = sim)#append simulated data to results data frame df_sim <-rbind(df_sim, temp)}#' the above is based on simulating data from the distributiondf_rib <-data.frame(x1 =numeric(), lb =numeric(), hb =numeric())for(i in x1) { q <-qnorm(c(.025, .975), mean = lm_sim$coefficients[[1]] + lm_sim$coefficients[[2]]*i, sd =1) temp <-data.frame(x1 = i, lb = q[1], hb = q[2]) df_rib <-rbind(df_rib, temp)}reg_plot <- df_sim %>%ggplot(aes(x = x1, y = sim)) +geom_point(data = df1, aes(x = x1, y = y), alpha = .1) +geom_ribbon(data = df_rib, aes(x = x1, ymin = lb, ymax = hb, y = hb), alpha = .2, fill ="steelblue") + ggdist::stat_halfeye(alpha = .8, fill ="navyblue") +geom_smooth(data = df1, aes(x = x1, y = y), alpha = .4, method ="lm", color ="firebrick4", fill ="firebrick4") +labs(title ="Conditional distribution for linear regression",subtitle ="The plot shows raw data and simualted data from regressing y on x1.\nRed line is line of best fit, gray area is 95% prediction interval",y ="y") +theme_minimal()
You can see an animated version of the plot to make it more readable:
The plot above is quite packed with information so lets unpack it. First, we have the datapoints plotted as a scatterplot. Next we have the red line which indicates the regression line or in other words the conditional means of y given x1. The we have the distributions which are data simulated from the model for 10 values of x1. Each distribution is what we would expect y to look like given a value of x1 based on our model. Notice that the mean of each distribution (the black dot) passes exactly through the red line. Next notice that each distribution has the same shape (pretty much a normal distribution - that is the normal distribution assumption) and more or less the same width (that is the homoscedacticity assumption. The light blue area indicates where we would expect 95% of the y to fall in for any given value of x1.
Now it’s time to introduce some data we can work on. We will be working with a dataset that stores information from 2010 General Social Survey. the dataset can be found in the openintro package (which stores data from various open source textbooks). Lets load the dataset and take a look at it.
library(openintro)data("gss2010")str(gss2010)
tibble [2,044 × 5] (S3: tbl_df/tbl/data.frame)
$ hrsrelax: int [1:2044] 2 4 NA NA NA NA 3 NA 0 5 ...
$ mntlhlth: int [1:2044] 3 6 NA NA NA NA 0 NA 0 10 ...
$ hrs1 : int [1:2044] 55 45 NA NA NA NA 45 NA 40 48 ...
$ degree : Factor w/ 5 levels "BACHELOR","GRADUATE",..: 1 1 5 5 5 5 4 4 3 3 ...
$ grass : Factor w/ 2 levels "LEGAL","NOT LEGAL": NA 1 NA 2 2 1 NA NA 2 NA ...
The dataset stores information on 5 variables: number of hours for relaxing after and average work day, number of days during the last 30 days in which participants mental health was not good, number of hours worked per week, degree and opinion on legalizing marihuana. (the docs are also available here). For now we will be mainly intersted in the hrsrelax variable and explaining it with hrs1.
We can start with the null model - a model that has no predictors, just the intercept in it. As we already know this intercept will in fact be the sample mean. Intercept can be coded with 1 in the formula. Running a regression in R is actually super simple. You can use the lm() function to do it.:
null_model <-lm(hrsrelax ~1, gss2010)
We can inspect the output using summary():
summary(null_model)
Call:
lm(formula = hrsrelax ~ 1, data = gss2010)
Residuals:
Min 1Q Median 3Q Max
-3.6802 -1.6802 -0.6802 1.3198 20.3198
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.68024 0.07741 47.54 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.63 on 1153 degrees of freedom
(890 observations deleted due to missingness)
This summary tells us the following:
the formula and data used for the model (under the “Call”)
Rough approximation of the distribution of residuals
The coefficients: the estimated Intercept equal to 3.68, its standard error and associated t and p values. This is equal to the mean of the hrsrelax variable: 3.68
The residual standard error (which in the case of the null model is just the standard deviation of the variable) and degrees of freedom
The number of deleted observations due to missing values. This one is real unfortunate as lm() will silently drop any missing values without so much as a warning! This can cause a lot of trouble so it’s worth always inspecting how many observations were in fact dropped.
Once we add predictors we will also get an omnibus F test statistic and its p value as well as an R squared value.
Lets add the first predictor to our model. The model will then look like this
\[
Y_i \sim Normal(\mu_i, \sigma)
\]
\[
\mu_i =\alpha + \beta_1 * hrs1
\]
simple_fit <-lm(hrsrelax ~ hrs1, gss2010)
Now that we have our model lets proceed to interpret it:
summary(simple_fit)
Call:
lm(formula = hrsrelax ~ hrs1, data = gss2010)
Residuals:
Min 1Q Median 3Q Max
-4.865 -1.710 -0.360 1.212 20.640
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.11038 0.21953 23.279 < 2e-16 ***
hrs1 -0.03501 0.00506 -6.919 7.56e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.579 on 1149 degrees of freedom
(893 observations deleted due to missingness)
Multiple R-squared: 0.03999, Adjusted R-squared: 0.03916
F-statistic: 47.87 on 1 and 1149 DF, p-value: 7.564e-12
What this output tells us is:
for a person who works 0 hours per week we expect 5.11 hours of relax time per day on average.
With each additional hour worked per week we expect .035 hours of relax time less. This means that we expect people whose work time per week differs by 10 to have on average .35 hour difference in their time for relaxation per day. This effect is significant at conventional levels.
The model dropped 893 observations which had missing values in any of the variables used in the model. Notice that it’s a lot!
The model explains about 4% of variance in hrsrelax variable and the F statistic is also significant. This means we were able to reduce the squared erros by 4% compared to the null model.
A note on assumptions
A lot of psych statistic courses has an obsession with assumptions for statistical tests. You may have heard such terms as normality, independence or homoscedacticity. They sound very scary and often intimidate students into running all sorts of tests to check for those assumptions and state things like “oh no that test for normality was violated I cannot use a parametric test!”. Truth is you always make assumptions of some sorts (even of the sorts like “my measurement tools actually worked”) and there is no running away from them. Rather than blindly checking assumptions it is much better to actually understand how they impact your model - what is affected if one of the assumptions gets violated and can we do something to deal with it? Here is a great post on precisely this topic.
Categorical predictors
Simple OLS regression is actually quite flexible in what kinds of predictors it can use. You can easily include various categorical predictors into your linear model. The trick is to code them properly.
Remember that the regression coefficient from a linear model tells us what is the predicted difference in Y for 1 unit increase in x? We can use that to code categorical predictors. For those variables that have only 2 levels (e.g. control and experimental condition) you code one as 0 (this level is called the reference category) and the other as 1. Then a 1 unit increase in x is simply the shift from the category coded as 0 to the category coded as 1. Lets look at an example. Lets see if people who want or do not want legalization of marijuana differ in the amount of time they have to relax:
Call:
lm(formula = hrsrelax ~ grass, data = gss2010)
Residuals:
Min 1Q Median 3Q Max
-3.7307 -1.7307 -0.6648 1.2693 20.2693
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.66477 0.13934 26.301 <2e-16 ***
grassNOT LEGAL 0.06589 0.19748 0.334 0.739
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.614 on 699 degrees of freedom
(1343 observations deleted due to missingness)
Multiple R-squared: 0.0001592, Adjusted R-squared: -0.001271
F-statistic: 0.1113 on 1 and 699 DF, p-value: 0.7388
This output is quite similar but the coefficients require a bit more attention now. What the output tells us is that people who want legalization of marijuana have on average 3.67 hours for relaxing per day. This is coded by the intercept. People who do not want legalization of marijuana have on average .07 hours more for relaxing per day. This difference is not statistically significant. Notice that we are silently dropping 1343 observations which is most of our sample! In this model LEGAL was coded as the reference category by default. This is because unless specified otherwise R will use the category that comes first alphabetically as the reference category. You can change it to set a different reference category with relevel():
Call:
lm(formula = hrsrelax ~ grass, data = gss2010 %>% mutate(grass = relevel(grass,
ref = "NOT LEGAL")))
Residuals:
Min 1Q Median 3Q Max
-3.7307 -1.7307 -0.6648 1.2693 20.2693
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.73066 0.13994 26.660 <2e-16 ***
grassLEGAL -0.06589 0.19748 -0.334 0.739
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.614 on 699 degrees of freedom
(1343 observations deleted due to missingness)
Multiple R-squared: 0.0001592, Adjusted R-squared: -0.001271
F-statistic: 0.1113 on 1 and 699 DF, p-value: 0.7388
The output is pretty much the same with intercept and dummy swapped. Now the intercept codes the mean number of hours of relax time for those who do not want legalization of marijuana and
In case you were wondering, yes we just did a simple t test. We can compare the results to the output of t.test() function:
t.test(hrsrelax ~ grass, gss2010)
Welch Two Sample t-test
data: hrsrelax by grass
t = -0.33333, df = 665.97, p-value = 0.739
alternative hypothesis: true difference in means between group LEGAL and group NOT LEGAL is not equal to 0
95 percent confidence interval:
-0.4539979 0.3222253
sample estimates:
mean in group LEGAL mean in group NOT LEGAL
3.664773 3.730659
So far we had only 2 levels of our categorical predictor. However, often you have to work with variables that have multiple levels. In such case you can no longer code one level as 0 and the other as 1. There are a few ways in which you can deal with this. We’ll look at two: dummy coding and effect coding.
Dummy coding extends the logic of coding categorical variables as 0 and 1. We still have one level as reference category coded as 0. Other levels are coded as 1 but this time we need 1 variable for each of those levels. We end up with k-1 variables that take values of 0 or 1 where k is the number of levels that a variable has (these are called dummy variables). Each dummy variable is coded 1 if it takes the value of a corresponding level and 0 otherwise. We have k-1 dummy variables because we do not need a variable for the reference level. If all the dummy variables take the value of 0 then we know it has the value of the reference level. Each of the dummy variables is going to express the difference between the reference level and a given dummy level. Note that this coding itself does not allow to compare 2 dummy levels to each other (we’ll see how to do that later). Lets see this type of coding in action. We will see if number of hours for relaxing after work differs among people with different degrees:
before we do it lets look up the levels of degree variable:
Call:
lm(formula = hrsrelax ~ degree, data = gss2010)
Residuals:
Min 1Q Median 3Q Max
-3.7918 -1.7761 -0.4779 1.2082 20.4681
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.4779 0.1667 20.859 <2e-16 ***
degreeGRADUATE 0.1931 0.2692 0.717 0.473
degreeHIGH SCHOOL 0.3139 0.2017 1.557 0.120
degreeJUNIOR COLLEGE 0.0540 0.3185 0.170 0.865
degreeLT HIGH SCHOOL 0.2509 0.2940 0.853 0.394
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.631 on 1149 degrees of freedom
(890 observations deleted due to missingness)
Multiple R-squared: 0.002415, Adjusted R-squared: -0.001058
F-statistic: 0.6953 on 4 and 1149 DF, p-value: 0.5953
Since bachelor is first alphabetically it was coded as the reference category. All other dummy variables code comparisons between the reference category and a given level. We can see the for people with bachelor degree we expect 3.48 hours of relax time per day on average. All other degrees are expected to have more relax time on average but none of the comparisons is statistically significant. Again we are dropping a lot of observations.
The other way to code a categorical variable is through effect coding. This type of coding will use intercept as the grand mean and each variable will reflect the difference between the grand mean and a given level. Not that again we have k-1 variables because the last comparison is just a function of the other ones.